新gss模型设计+双跑
GSS新模型-重构思路
利用 MongoDB 对现有业务、未来可支持的业务进行数据建模,建立起多个数据模型,分别适用于不同类型的业务。
GSS新模型-CVS配置
GSS 的 CVS 配置从时间成本、安全隐患、后期维护的角度考虑,不再重新建表。
在旧的 define_hisgss 中,为每个要迁移的业务新建一个新的配置,用于双跑。双跑后期,将老 hid 对应的配置修改为新配置,具体细节见下面的双跑思路。
不同模型的在 define_hisgss.model 中的字段配置和含义见下方的 GSS 新存储模型介绍。
字段
0)配置管理字段
字段所需位置:
好像没有具体需要的位置?仅仅是为了方便管理。
"hid":唯一配置id,此字段没有实际作用,仅为了方便管理。
1)解析配置时必要字段
字段所需位置:
【SearchDomain.cpp 】->【CSearchDomain::Init(const Json::Value & root) 】
"type":GSS的存储模型类型,用来对应不同的类。此字段对任何模型都必须。
2)CSearchModel 基类字段
"pidfield":实体字段,指定哪个字段代表实体ID。此字段必须,但在Mongo模型中无用。"keepday":生命周期,检索信息保留的时间,过期将被清除;统一以日为单位,0表示永久保留。此字段不配置的情况下默认为0,在 mongo 模型中,此字段不起作用,仅为了方便管理和查询,doc 的 TTL 由 mongo 数据库通过索引实现。"rollingcycle":无实际意义。滚动周期,模型实际存储滚动的周期,可以为:日、周、月、季、年、永久(默认)。此字段必须,但在Mongo模型中无用"tablename":表名,从 mysql 遗留的字段。此字段必须,但在Mongo模型中无用"clusterName":所属集群名。当前无实际意义。此字段非必要。且没有业务使用此字段。此字段可以缺失,且在Mongo模型中无用
3)数据库连接信息
"mongoCluster":使用的MongoDB集群。【这个字段应该不需要】"mongoDatabase":使用的MongoDB数据库。【这个字段可能也不需要?】"mongoCollection":使用的MongoDB集合。【这个字段可以考虑用上面的tablename来代替】
上面的三个字段需要后续和暴常军讨论,再决定是写在配置里还是直接硬编码就可以了。
OSS中Mongo的连接配置就是直接硬编码的。
4)mongoModel 类型通用的字段
"keyfields":doc 中作为检索的字段。【需要注意的是,这里的顺序应该与索引顺序一致】- 查改删的时候:直接按照此处配置的字段解析接口中的
- 增的时候:先从从entity(用户信息)中查找,然后从info(索引字段)中查找。
"valuefields_public":doc 或 array 中作为信息数据存在的字段。不同实体相同的信息。- 新增的时候:先从info(索引字段)中查找,然后desc(比赛信息)查找。
"valuefields_entity":doc 或 array 中作为信息数据存在的字段。不同实体独立的字段。- 新增的时候:先从entity(用户信息)查找,然后从info(索引字段)中查找。
"maxlength":同一个索引中保留的最多信息条数(array中保留的数据条数)"whitelist":白名单列表(需要的时候设置,不需要的时候不需要该字段)"whiterange":白名单范围(需要的时候设置,不需要的时候不需要该字段)
5)不同模型中的独有字段
- mongoArrayModel:
- 【无】
- mongoSingleModel:
- 【无】
- 【占位】
配置实例
以一个用于迁移的新 mongoArrayModel 类型的业务为例:(斗地主近20次夺冠时间,ddzbtime)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
{
"hid": 72602,
"type": "mongoarraymodel",
"pidfield": "",
"rollingcycle": "",
"tablename": "",
"keepday": 0,
"maxlength": 20,
"keyfields": [
"pid",
"mpid"
],
"valuefields": [
"mpid",
"at"
],
"whitelist": [
{
"key": "rank",
"values": [
1
]
}
],
"mongoCluster": "mongo_hisgss",
"mongoDatabase": "GSS_test",
"mongoCollection": "testDDZBTIME"
}
老配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
"hid": 2602,
"type": "filterlist",
"namespace": "DDZBTIMEMPID",
"partitionfield": "mpid",
"pidfield": "pid",
"rollingcycle": "permanent",
"tablename": "ddzbesttime",
"maxlength": 20,
"valuefields": [
"mpid",
"at"
],
"entityinfo": [],
"whitelist": [
{
"key": "rank",
"values": [
1
]
}
]
}
GSS新模型-存储模型
保留的老模型
保留的模型有两类:
-
使用 MySQL 的业务。包括 录像 和 奖状 两个大业务,因为 WEB 那边有的是直查 MySQL,不太好让他们做修改。
-
内部包含处理逻辑、不是单纯数据模型的业务:例如 GSS 模型为 normallist 的 比赛回顾 的几个业务;比赛模型为 normalrecordmodel 的 本地录像 业务;包含复杂逻辑补丁的业务,例如使用 hash 的 “JJ直播家族改”、使用 filterlist 的 “JJ直播”。
这几个模型如果要迁移的话,就要考虑怎样处理其中的逻辑判断,如果要迁移的话,有以下几个思路:
- 在 GSS 以 mongo 为基础,为上述业务定制化创建对应的模型。相当于用 mongo 重写上面提到的那几个定制模型。
- 将这几个业务进行拆分,把数据存储和逻辑判断拆开,将逻辑判断放到 Store 中,相当于在 Store 中为这几个业务打了一堆补丁,处理定制化的业务逻辑。
- 再详细研究一下这几个业务,看看能否抽象出 “包含简单逻辑的数据模型”,如果可以的话就在 GSS 中创建这几个数据模型。难点:初步评估不太好弄、并且有新旧模型处理结果不一样的隐患。
MongoArrayModel
1. 模型方案
-
主要使用 MongoDB 中的 array 结构做数据存储。
-
提供 filter 筛选功能:针对目标字段做筛选,符合条件的数据才会写入。类似白名单。
-
doc 过期:先评估业务数据量,然后联系 DBA 确定采用以下哪种方式过期数据:
- 业务数据量小:将 “UpdateAt” 字段设置为 TTL 索引,并设置过期时间。
- 业务数据量大:DBA 设置定时任务,在低峰期(凌晨1~4点)按照 “UpdateAt” 字段过期数据。
-
doc 中的 array 各个元素的过期解决方案:【初步】
-
不实现这个功能
-
在 array 的每个元素中也增加字段 “lastModifyTime”,用于记录最后一次修改的时间。在每次【查询】的时候,筛选出整个 array 中过期的元素,全键指定元素,执行删除。
选择在 “查询” 而非 “写入” 时删除的原因:HIS 是一个高写低读的服务,有的业务的读写比例甚至能达到1:100。而 array 中过期单个元素这个功能的又比较复杂,因此在低频率的“查询”时来做这件事较为合理,可避免给MongoDB服务器带来大量的ops。
-
-
doc 中 array 支持按照最大长度截断,且要求每个业务必须要设置最大长度。
-
基本功能:提供 “增删改查” 4个基本功能,均是针对 array 中的元素进行操作的。
注意点:4 个基本功能尽量保证都是原子操作,至少保证不会线程冲突。
-
文档数据结构:
- key:文档索引。
- time:”createAt” 和 “updateAt” 两个时间戳。
- value-array:一个数组,用来记录所有的数据。
-
【占位】
2. 模型特点
1)优点
- 支持多源写入。例如“赛程回顾”业务。
- 查询速度较快(不考虑 array 中单个元素按照时间过期功能的情况下)。匹配到结果后可以直接返回一个 array,一次 search 就能满足要求。
- 自然支持按照最大长度截断的功能。
2)缺点
- 不好实现 array 中单个元素按照时间过期的功能。
- 写入速度不如单独插入一个 doc 快。向目标 doc 的 array 插入一个新元素时,实际是调用的 update 方法。
- “删除” 或 “更新” 有隐患。通过条件能匹配到 array 中的多个结果时,是否都删除/更新?解决方法:
- 通过限制字段数量,增加安全保护
- 考虑该模型不要支持 “删改” 功能
3)适用业务
- 需要多源写入的业务。
- 最近 N 条类型的业务。且 N 的条数比较少。
3. MySQL 配置
- 具体细节有待设计
1)CVS配置
1)key
- doc 的组成部分,作为索引键存在。
- 在 MongoDB 中建表的时候将这些字段指定为索引。
- 增删改查时,通过 key 中的字段定位目标 doc。
- MySQL 配置示例:
- Mongo 文档内容示例:
- 【占位符】
2)value
- doc 的组成部分,作为存储内容存在。
3)filter
- 生成 doc 时的筛选条件,类似于白名单。
4. 基本功能
- 待完善
5.业务示例
索引设置
| Name & Definition | Type | Size | Properties | Status | |
|---|---|---|---|---|---|
| _id_ | regular | 16.0 MB | unique | Ready | |
| updateAt_1 | regular | 12.9 MB | TTL | Ready | |
| userid_1_gameid_1_mpid_1 | regular | 34.1 MB | unique compound | Ready |
上表的 Size 是在有效数据为 5000W 条、ModelArray 表中 doc 个数为 50W 个时的数据。
Document示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
{
"_id": {
"$oid": "6790c223b6a028b5bf30364a"
},
"createAt": {
"$date": "2025-01-22T08:21:08.448Z"
},
"updateAt": {
"$date": "2025-01-22T08:21:08.448Z"
},
"gameid": 1105,
"mpid": 77080,
"userid": 10000001,
"gamedata": [
{
"round": 57,
"result": "Win",
"role": "Prince",
"_id": "6790615ca6faf6b3a1a8f40a",
"_ts": {
"$date": "2025-01-22T03:09:16.490Z"
}
},
{
"round": 57,
"result": "Win",
"role": "Prince",
"_id": "6790615ca6faf6b3a1a8f579",
"_ts": {
"$date": "2025-01-22T03:09:16.687Z"
}
}, ...
]
}
MongoSingleModel
1. 模型方案
- 一个 doc 就是一条记录,查询的时候通过聚合语句查询多条结果,整理后返回。
- 提供 filter 筛选功能。
- doc 过期,也就是每条记录的过期。与 MongoArrayModel 一样:业务量大的话走 DBA 定时任务,任务量小直接设置 TTL。
- 不提供最大长度截断的功能,因为不需要,按照时间戳 “updateAt” 过期就行。客户端想取多少自己传参。
- 基本功能:提供 “增删改查” 4个基本功能,均是针对单个 doc 进行操作的。
- 文档数据结构:
- key:文档索引
- time:”createAt” 和 “updateAt” 两个时间戳。
- value-single:单个的键值对,用于记录所需的数据。
- 【占位】
2. 模型特点
1)优点
- 写入速度较快。因为每次都是单独插入一条新的文档。
- 方便实现 “删改” 的功能。因为一条 doc 就是一条记录,匹配到结果后直接对目标 doc 执行即可。
- 方便实现针对doc过期的功能。此模型下的每条索引,自然与OSS中的content生命周期一致。不会出现查到了索引,但是通过索引中的oid查找不到content的情况。
- 此种模型下可以考虑将 content 直接存到 GSS 里,不用担心倾斜的情况。
2)缺点
- 查询速度较慢。因为需要根据条件聚合。
- 不好实现最大长度截断的功能。解决方案:不实现最大长度截断,按照 TTL 过期即可。
- 将 MongoDB 按照结构型数据库来使用了,看起来有些笨。那为啥不直接用 MySQL?
3)适用业务
- 插入后需要 “删改” 的业务。
3. MySQL 配置
- 待完善
4. 基本功能
- 待完善
5.示例
索引设置
| Name & Definition | Type | Size | Properties | Status | |
|---|---|---|---|---|---|
| _id_ | regular | 1.6 GB | unique | Ready | |
| updateAt_-1 | regular | 941.0 MB | TTL | Ready | |
| userid_1gameid_1_mpid_1_updateAt-1 | regular | 3.1 GB | unique compound | Ready |
上表的 Size 是在有效数据为 5000W 条、ModelSingle 表中 doc 个数为 5000W 个时的数据。
Document示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"_id": {
"$oid": "6790aa74acfaace9b517ab59"
},
"userid": 10000006,
"gameid": 1105,
"mpid": 77019,
"round": "66",
"result": "Draw",
"role": "Emperor",
"createAt": {
"$date": "2025-01-22T08:21:08.448Z"
},
"updateAt": {
"$date": "2025-01-22T08:21:08.448Z"
}
}
GSS双跑-设计
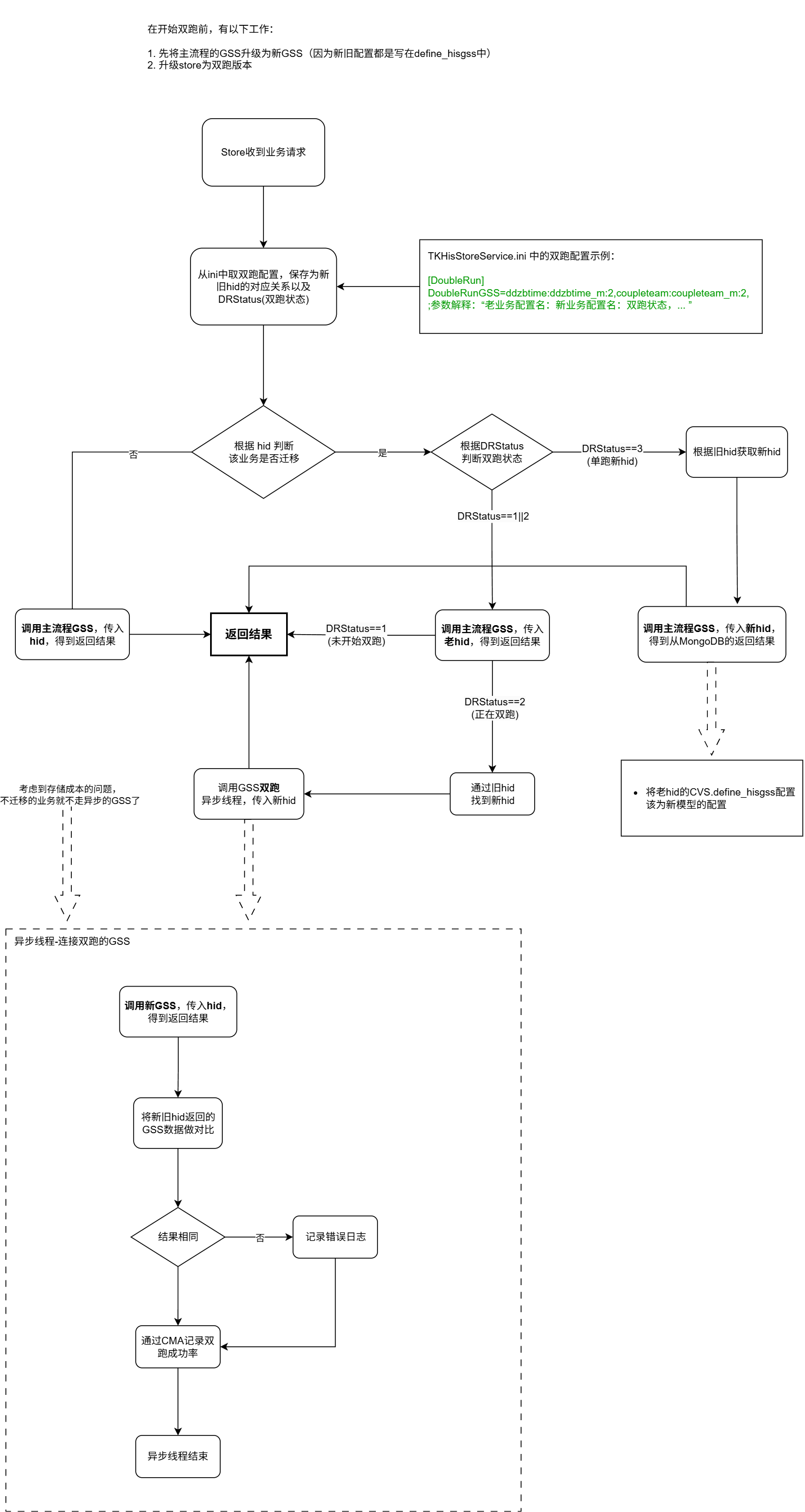
GSS双跑-测试点
-
DWStatus 的三种状态测试。
- 1:主流程通过老配置读写。
- 2:主流程通过老配置读写 + 双跑支路通过新配置读写。
- 3:主流程通过新配置读写 + 双跑支路通过老配置写入。
- 4:主流程通过新配置读写。
-
支路GSS崩掉。【现象:】store会有发送失败的报错,并在日志中输出(如下所示)。
03/20/25 00:00:30 00001328
CreateSearchInfo 向GSS发送消息失败,errtype:3 03/20/25 00:00:30 00000980 SendMsgInternal_3 connect failed : ErrorType=3, MstType=0x00036400, Len=114, Dst = 192.168.7.101 : 30711 -
store升级为双跑版本后,如果不配置TKService.ini中双跑支路的连接信息会怎样。
-
新GSS对业务走老配置是否有影响。
-
在CVS中建一个新的mongo集群配置表
define_mongo_cluster。 -
GSS加载
CVS.define_mongo_cluster配置失败。【现象:】store尝试从本地加载配置,日志输出如下。03/20/25 16:57:35 00001a14
CVS没有有效的MongoDB集群配置,尝试从本地Json文件中加载MongoDB集群配置... 03/20/25 16:57:35 00001a14
从本地Json文件中更新MongoDB集群配置连接失败,没有成功加载任何集群! 03/20/25 16:57:35 00001a14 mongo集群定时更新配置连接失败! -
从his集群到负责双跑的marker集群的30711端口是否连通。
-
CVS配置:要迁移的 GSS 业务的新旧配置都写在表 define_hisgss 中。通过hid来区分业务的新旧配置。
-
双跑的业务:全量业务双跑,包括:待迁移业务、不迁移的业务。这样可以最大程度保证双跑支路的 GSS 的可用性。
GSS双跑-布置相关的ip
1)所有需要开通 mongo-gss 的ip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
his集群的8台机器:
10.30.127.11
10.30.127.12
10.30.127.13
10.30.127.14
10.30.125.211
10.30.125.212
10.30.125.213
10.30.125.214
用于双跑的marker的4台机器:
10.30.20.246
10.30.20.247
10.30.20.248
10.30.20.249
GSS双跑-布置要点
1)增加CVS配置信息
map_define2cluster
在 map_define2cluster 中为表 define_mongo_cluster 新增解析路径。
可以参考之前的配置表 define_oss_cluster。
map_node2cluster
在该表中增加4台marker机器的30711端口到 hisgss 集群。
define_mongo_cluster
在该表中增加新的、为gss提供的 mongo 集群信息:
1
2
3
4
5
6
7
1)架构:分片集群
2)主机地址(host):service.jjsrv.local
服务名(srvServiceName):hisgss-001-mongodb
3)业务账号:srv_hisgss_rwl
4)业务密码:其他方式通知
5) 业务库:db_hisgss_qipai、db_hisgss_xiaoyouxi
6)密码:V02augh9HKO18O7x
2)使用新表define_mongo_cluster
- 内外网创建表 define_mongo_cluster,并添加对应的数据。
- 修改oss和gss代码,由 define_oss_cluster 改为使用 define_mongo_cluster 。
3)布置双跑支路的GSS.exe
- 选择HIS-Marker集群的四台机器作为双跑GSS支路。
- 开放这4台机器的30711端口。
- 为这4台机器申请his-redis的数据库权限。
- 拷贝所需的配置(见压缩包
gss-marker.zip)到4台目标机器上。 - 为这4台机器申请所需的MySQL库(hissingle-001-mysql 和 his-001-tidb)权限。
- 将HIS-Marker集群添加到AOM中。
4)布置双跑的Store.exe
-
增量修改所有HIS集群下的
TKHisStoreService.ini的配置:1 2
[DoubleRun] DoubleRunGSS=ddzbtime:ddzbtime_m:1,coupleteam:coupleteam_m:1,jjzbgg:jjzbgg_m:1,zjzlist:zjzlist_m:1,zjzplayer:zjzplayer_m:1,rankhis:rankhis_m:1,newrankhis:newrankhis_m:1,mpcard:mpcard_m:1,bingorec:bingorec_m:1,pfight:pfight_m:1,gdrank:gdrank_m:1,recgamelist:recgamelist_m:1,recanchorlist:recanchorlist_m:1,zjsyhzj:zjsyhzj_m:1,xqlx:xqlx_m:1,AI30his:AI30his_m:1,AI1v1:AI1v1_m:1,SJAI1v1:SJAI1v1_m:1,TYAI30his:TYAI30his_m:1,Anchor30his:Anchor30his_m:1,AnchorCards:AnchorCards_m:1;
-
增量修改HIS集群的
TKService.ini配置:1 2 3
[TKHisStoreService] ;双跑GSS的连接信息 TKGeneralSearchService_Mongo_SPIF=10.30.20.246:30711:200,10.30.20.247:30711,10.30.20.248:30711,10.30.20.249:30711
-
将HIS集群的所有store.exe升级为双跑功能的store。
GSS双跑-详细设计
双跑详细流程
-
完成GSS编码。保证接口不变,在Model中新增使用MongoDB的模型,通过hid与CVS配合使用。
-
完成Store编码。在Store中搭建双跑系统,配合store.ini实现双跑逻辑(见本md文档同路径的流程图:
2025新GSS双跑设计.drawio) -
内网测试。按照如下流程测试双跑流程和正式流程。
-
向DBA申请如下资源:【MySQL和redis直接用内网的够用吗】
- MongoDB资源。用于GSS双跑和正式使用。并提前创建目标业务的表、按照业务配置设置好索引。
-
搭建GSS双跑环境。在4或8台机器上布置双跑的GSS。搭建双跑环境可参考:
HIS-双跑准备+升级服务.md -
升级老GSS服务。因为新旧gss业务都是写在同一张
define_hisgss表上,如果老GSS不升级的话就会导致CVS配置解析失败。(这里会有一定隐患:因为GSS修改的比较多,如果对老业务造成影响的话,这里会出问题,因此在这一步之前,需要对新GSS做充分测试) -
修改CVS配置。将要迁移的业务,按照新MongoDB模型,写好配置,新旧配置都放在 define_hisgss 中。
-
修改 store.ini 配置。将所有需要迁移的业务配置在store.ini中。配置示例如下:
1 2 3
[DoubleRun] DoubleRunGSS=ddzbtime:ddzbtime_m:2,coupleteam:coupleteam_m:2, ;参数解释:“老业务配置名:新业务配置名:双跑状态,... ”
-
升级所有的Store服务(主流程和双跑支路)。但此时还未开始双跑,因为ini中配置的双跑状态默认为1。
-
开始双跑。修改 store.ini 配置,将双跑状态统一修改为 2,开始向支线 GSS 双跑。
-
双跑一段时间,观察双跑成功率的状态,确定新 GSS.exe 服务没有问题。保证MongoDB中的数据与redis全量相同,且从新老GSS中获取的数据均一致。
-
将“要迁移业务”的读取请求切到双跑支路。修改 store.ini 配置,双跑状态统一修改为 3,此时,store 针对“要迁移业务”,将旧hid转为新hid,仅通过主流程的GSS传入新hid获取新的来自MongoDB的结果。
-
修改CVS配置,将老hid的配置改为新的使用MongoDB的模型配置。修改 store.ini 配置,双跑状态统一修改为 4,此时,store 使用新hid 配置,通过主流程从 MongoDB 读写。老 hid 配置不再使用。此时可以放心修改老 hid 的内容。
-
修改 双跑状态为1,此时,主流程的GSS通过老hid的配置从MongoDB读写新的数据。
-
双跑结束。将store服务替换为没有双跑代码的版本。(这一步可以不做)
-
回收双跑资源。
关键ini配置说明
1
2
3
[DoubleRun]
DoubleRunGSS=ddzbtime:ddzbtime_m:2,coupleteam:coupleteam_m:2,
;参数解释:“老业务配置名:新业务配置名:双跑状态(DWStatus),... ”
双跑 ini 配置中的 DWStatus 含义:
- 1:主流程通过老配置读写。
- 2:主流程通过老配置读写 + 双跑支路通过新配置读写。
- 3:主流程通过新配置读写 + 双跑支路通过老配置写入。
- 4:主流程通过新配置读写。
GSS双跑-双跑日志
1)操作日志
- 2025年4月2日15:50 升级外网Store和GSS服务。
- 2025年4月2日16:37 暴常军新建
t_zjzlist和t_zjzplayer两个业务表。 - 2025年4月2日17:07 修改了全量 8 台机器的配置,开始对这两个业务进行双跑。
- 2025年4月10日18:32 暴常军新建了一批业务表。
- 2025年4月10日18:35 开始双跑
rankhis业务。 - 2025年4月10日18:40 开始双跑
newrankhis业务。 - 2025年4月10日18:43 开始双跑
jjzbgg业务。 - 2025年4月10日18:47 开始双跑
zjsyhzj业务。 - 2025年4月10日18:49 开始双跑
xqlx业务。 - 2025年4月10日20:16 开始双跑
mpcard业务。 - 2025年4月10日20:20 开始双跑
coupleteam业务。 - 2025年4月10日20:25 检测到Marker的247机器CPU升高到98%,**2025年4月10日20:54 **。
- (其他的一些现象)
- 2025年4月10日20:54 关停了所有的双跑配置。
-
2025年4月10日21:12 MRK机器把剩余的消息写入完毕。
- 2025年4月15日11:52 打开了
zjzlist的双跑配置。 - 2025年4月15日20:17 打开了
zjzplayer、rankhis、newrankhis的双跑配置。 - 2025年4月15日20:33 打开了
xqlx的双跑配置。 - 2025年4月15日20:42 发现上面 4 个配置只开了集群A的四台机器。又打开了集群B的双跑配置。
- 2025年4月15日20:48 打开了
coupleteam的双跑配置。 - 2025年4月15日20:54 打开了
gdrank的双跑配置。 - 2025年4月15日20:57 打开了
recgamelist的双跑配置。 - 2025年4月15日21:01 打开了
mpcard的双跑配置。 -
2025年4月15日21:03 打开了
zjsyhzj、pfight、recanchorlist的双跑配置。 -
2025年4月22日16:06 开始双跑
AI30his、AI1v1、SJAI1v1、TYAI30his、AnchorCards、Anchor30his。 -
2025年4月22日16:39 发现AI复式赛集群的两台机器都没有升级和布置双跑。强升了这个集群的机器。
- 2025年5月21日17:53 通用集群,修改
AI1v1、SJAI1v1、AnchorCards(TTL为1)双跑配置为 3 。 - 2025年5月23日16:24 修改了
xqlx和zjsyhzj两个业务的外网配置,之前这两个业务白名单字段写错了,导致有多余数据写入。 - 2025年5月23日16:33 修改了
zjzplayer(TTL为20)双跑配置为 3 。 - 2025年5月23日16:47 AI复式赛集群 ,修改
AI1v1、SJAI1v1、AnchorCards(TTL为1)配置为 3 。
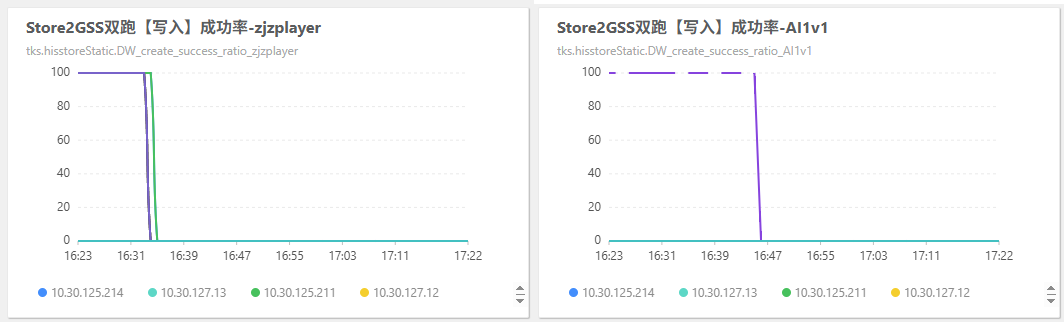
-
2025年5月28日15:20 修改了一些配置错误:
-
将外网
zjsyhzj_m业务mongo配置的 maxLen 字段由0改为99whiteRange 字段由 [0,2000000] 改为 [600501,620000]
-
将外网
zjzlist_m业务mongo配置的 maxLen 字段由30改为100、keepday字段由20改为30 -
将外网
pfight_m业务mongo配置的 maxLen 字段由30改为100 -
将外网
gdrank_m业务mongo配置的 maxLen 字段由10改为20 -
将外网
xqlx_m业务mongo配置的 whiteList 字段中添加 mpid [2003194]
-
-
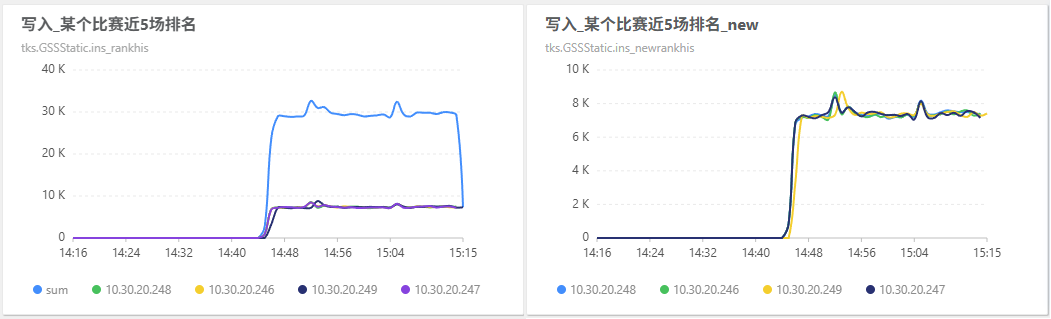
2025年5月30日14:45 修改
rankhis和newrankhis双跑配置为 3。其中 newrankhis(hid:2991)业务的读取量非常大,每分钟 40k 的查询量。
因为 newrankhis 的读取量非常大,切换之后,mrk 的查询量下降、 his 的查询量上涨。
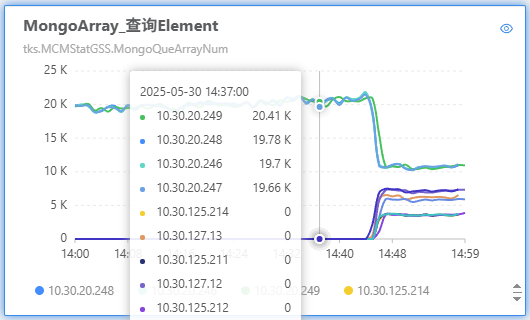
向 mongo 的查询请求延迟前后一致:
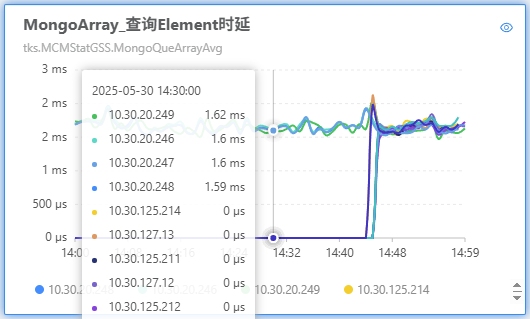
从业务侧来看,查询延迟上涨了一倍,这是因为 mongo 和 redis 的性能差异导致的:
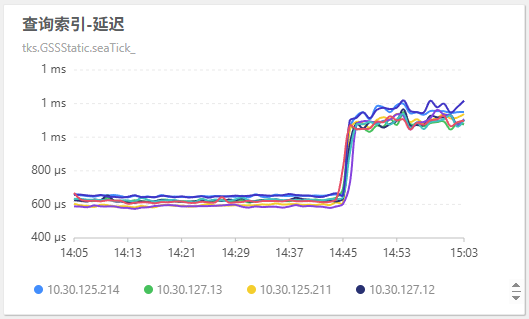
his 机器上的 redis 请求量变少了,所以整体读写性能表现更好了:
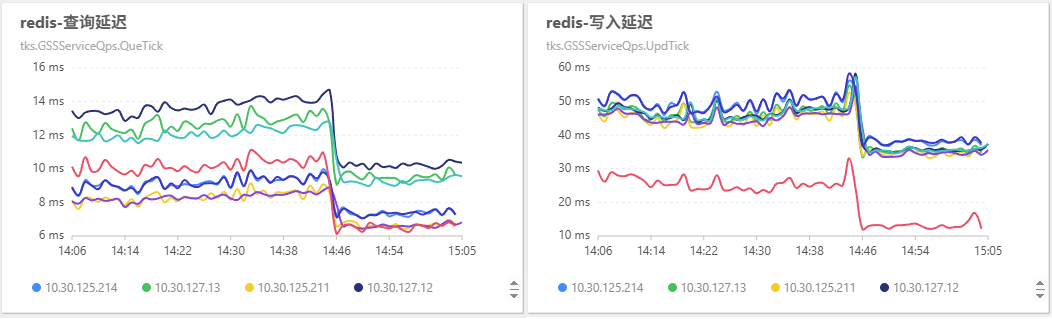
his 集群的 redis 查询总量从 140k 下降到 100k/min,写入总量从 600k 下降到 450k/min。
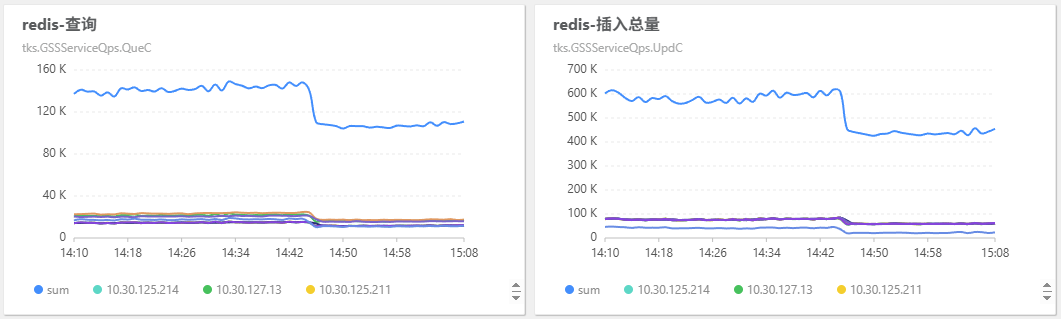
his 集群开始大量向 mongo 读写:
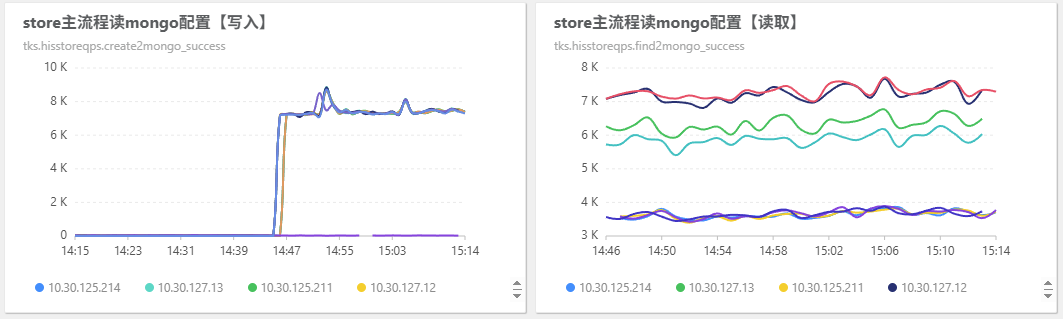
此时这两个业务的双跑 status 为 3,此时通过 mrk 集群向 redis 写入:
-
2025年5月30日16:15 收到客户端同事【邓锴】的反馈:客户端有大量报错,因此把 status 又改回了2。
-
2025年5月30日17:18 修改了
coupleteam业务的配置错误:keepday 由 3 改为 30。 -
2025年6月18日10:24:24 修改了
zjsyhzj业务的双跑状态为3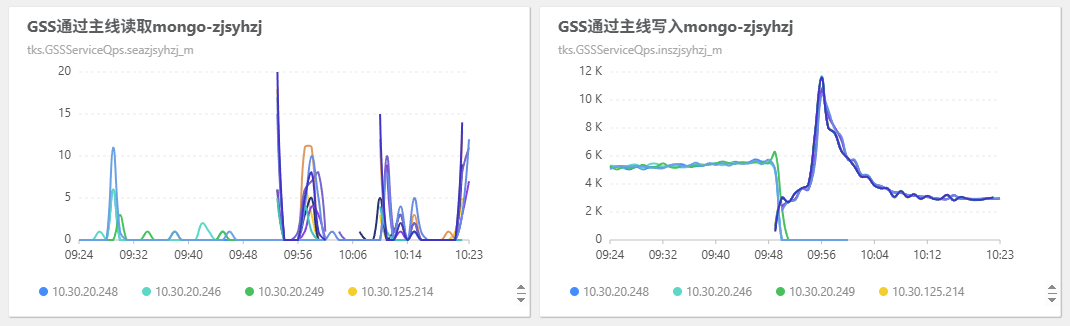
-
2025年7月2日09:41 修改了
coupleteam的双跑状态为3,这个业务的读写量都很大: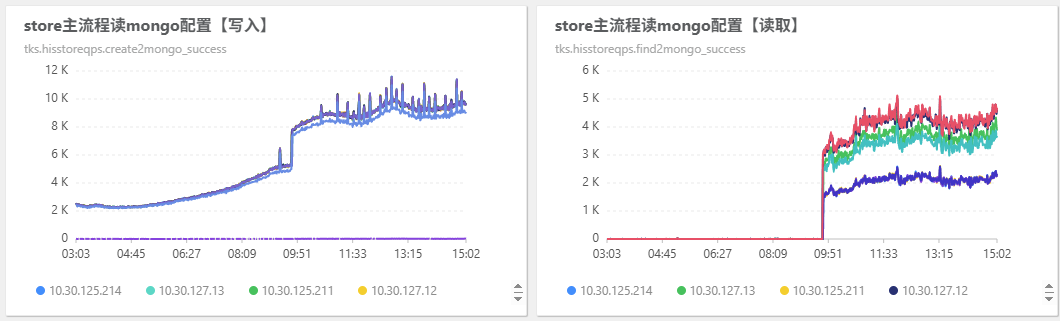
-
2025年7月2日15:16 修改如下业务的双跑状态为4:
1
zjzplayer, AI1v1, rankhis, zjsyhzj, SJAI1v1, mpcard, AnchorCards
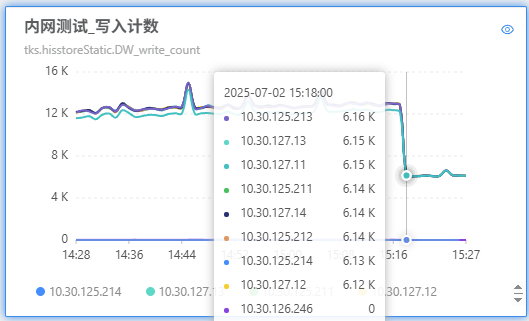
-
2025年7月3日13:59 修改如下业务在 define_hisgss 中的原配置为 mongo 配置:
1
zjzplayer, AI1v1, rankhis, zjsyhzj, SJAI1v1, mpcard, AnchorCards
-
2025年7月3日14:18 修改上述业务的双跑状态为 1 。这7个业务完全切换完成。
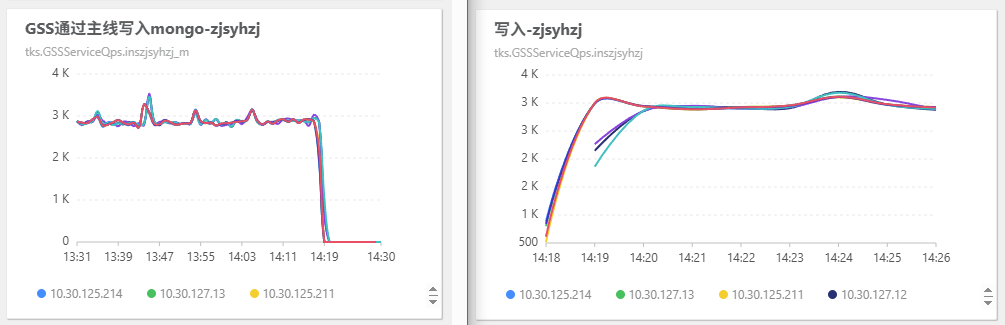
-
2025年7月29日18:19 修改 newrankhis 双跑配置为3。在 store 中删除已经双跑完毕的业务
-
2025年7月30日09:53 修改 store.ini 中
coupleteam和newrankhis的双跑状态为 4 -
2025年7月30日10:05 修改 define_hisgss 中
coupleteam和newrankhis老 hid 的配置为 mongo 版 -
2025年7月30日10:10 修改 store.ini 中
coupleteam和newrankhis的双跑状态为 1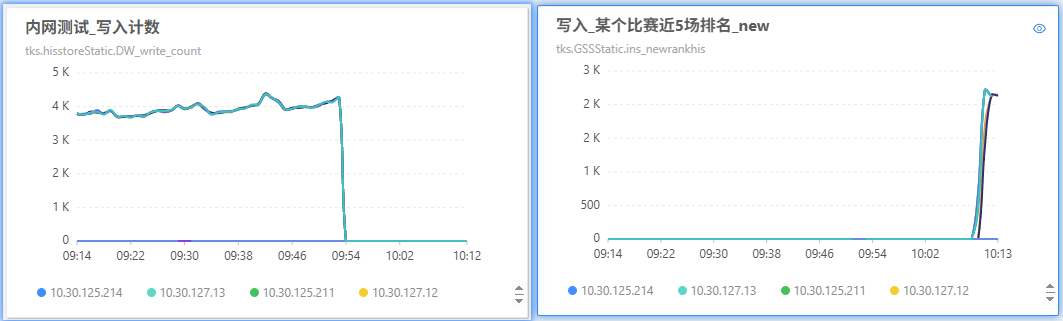
-
此时双跑支路的流量都为空,且mongo配置都以不在生效:
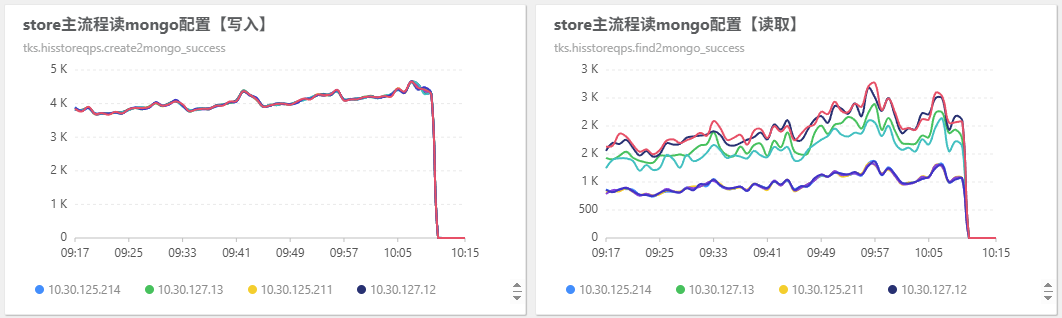
###2)双跑数据对比
- 测试环境:本地通过py脚本连接 10.30.127.11 和 10.30.20.246 两台机器上的 GSS,分别查询业务名 “zjzlist” 和 “zjzlist_m” 两个业务配置,也就是 redis 和 mongodb 中的数据。
- 测试内容:测试了返回的数组内容和数组长度”C”。
- 测试结果:返回的数组长度与实际一致;返回的数组内容一致,字段顺序不一样(但这个应该不影响)
3)双跑出现的问题
1. mongo 第一个数据不匹配
日志报错信息:
1
05/19/25 06:55:58 00002a7c <DoubleRunGSS> <ERR-FastSearchIndex_Async> 在对比到第 0 个元素时,字段 oid值不一致!redis 中的值为:7505817532004630594,mongo 中的值为:7506047017073311767,检索条件:searchdomain:mpcard_m,sContent:,sCondition{"CardId":"d681dc65f5555701b946625223223f14","pid":0},sOrder:,dwStart:0,dwLimit:200
原因:猜测 mpcard 这个业务会在写入后马上查询,因为 mongodb 是异步写入的,此时数据还没写入,会有一定的延迟,因此导致第一个数据对不上。稍等一会儿数据就都是一样的了。
2. redis 中部分数据缺失
日志报错信息:
1
2
3
05/22/25 06:57:22 00003998 <DoubleRunGSS> <ERR-FastSearchIndex_Async> 在对比到第 1 个元素时,字段 oid值不一致!redis 中的值为:7473955858284740812
,mongo 中的值为:7506936126842798233
,检索条件:searchdomain:xqlx_m,sContent:,sCondition:{"pid":112855760,"targetpid":112855760}
原因:业务xqlx存在白名单,外网的白名单字段写错了,导致白名单未生效。
3. 客户端-业务耦合问题
-
现象:切换了一个读写流量非常大的业务
newrankhis(hid:2991),his服务器和mongo表现符合预期。但客户端反馈有大量报错,平均每分钟有大约200条报错。经查,该报错是因为客户端存在业务之间的逻辑耦合导致的。客户端会先从2991拿数据,然后再以同样的索引从2601中拿数据,然后将2601中拿到的数据补充到2991中。本次报错的原因是因为从2991中拿到的数据少于2601,导致当将2601的数据试图插入2991时,会有多余的数据而溢出。
-
根本原因:mongo中新增了逻辑:清理超过ttl的数据,这样会保证mongo中的所有数据都是在ttl之内的。但redis中没有这个逻辑,是按照key来控制ttl的,只有当该用户从未在30天内打过该游戏,才会清理这个key。
-
解决方案:客户端在代码中去掉拿 2991 的逻辑。
-
数据对比验证:
- 目标:为了验证两个业务的数据内容是完全一致的,保证客户端切换前后没有影响。
- 内容:DBA全量对比了 2991(newrankhis)和 2601(coupleteam)两个业务在 redis 中的数据,一共有 310353077 条数据,其中有 11283 条不同,比例为万分之 0.364 。检查了不同的 key,是因为有数据错位导致的不同。数据错位的原因:在写入时有两场比赛结束的时间及其相近,redis同时收到两条业务的写入,两个业务写入的顺序不同。数据不同的比例和原因均可接受,解决方案可行。
4. 客户端-将str转为json失败
-
现象:切换了 3021(AI30his)、3041(TYAI30his)、3081(Anchor30his)导致客户端显示列表为空。
-
原因:从 gss-mongo 中的返回的字符串会有多余的空格。客户端在 lua 中使用自己写的 json 函数对字符串进行解析,之前的客户端是没有考虑空格的问题的,所以在解析数据时会把空格带上,一并放入表中,导致在获取数据时会出现问题。
1 2 3 4 5
// gss-redis 返回的字符串: [{"stageid":1,"tourneyid":115371}] // gss-mongo 返回的字符串: [ { "stageid" : 1, "tourneyid" : 115371} ]
-
解决方案1(客户端):客户端修改 lua 中解析转 json 的函数。但这样的时间周期比较长、比较麻烦。
-
解决方案2:重新评估了本次 his 双跑迁移的目标,迁移业务的数量和清理出 redis 的空间并不是主要的目标,甚至迁移多少一些业务都问题不大。因此这些会造成麻烦、迁移时间较长的业务本次就干脆不迁移了。于是在2025年6月11日下线了一批双跑业务,将这批业务改为不迁移。