Bug:CVS节点切换引发服务性能瓶颈
一、背景
HIS、EVT、MRK、DHL 等系统(原行为数据组下的所有系统)依赖两台 CVS 节点(22 机房10.22.125.11、31 机房10.31.125.18)提供配置服务。
之前是混合连接两台机器,近期,为配合原 30 机房设备回收,计划将所有业务的 CVS 链接从双节点负载,统一切换至 22 机房单节点 CVS 承载,或是申请新的机器代替 30 机房的 CVS。
二、操作过程
- 2026年4月24日18:01 将虚机
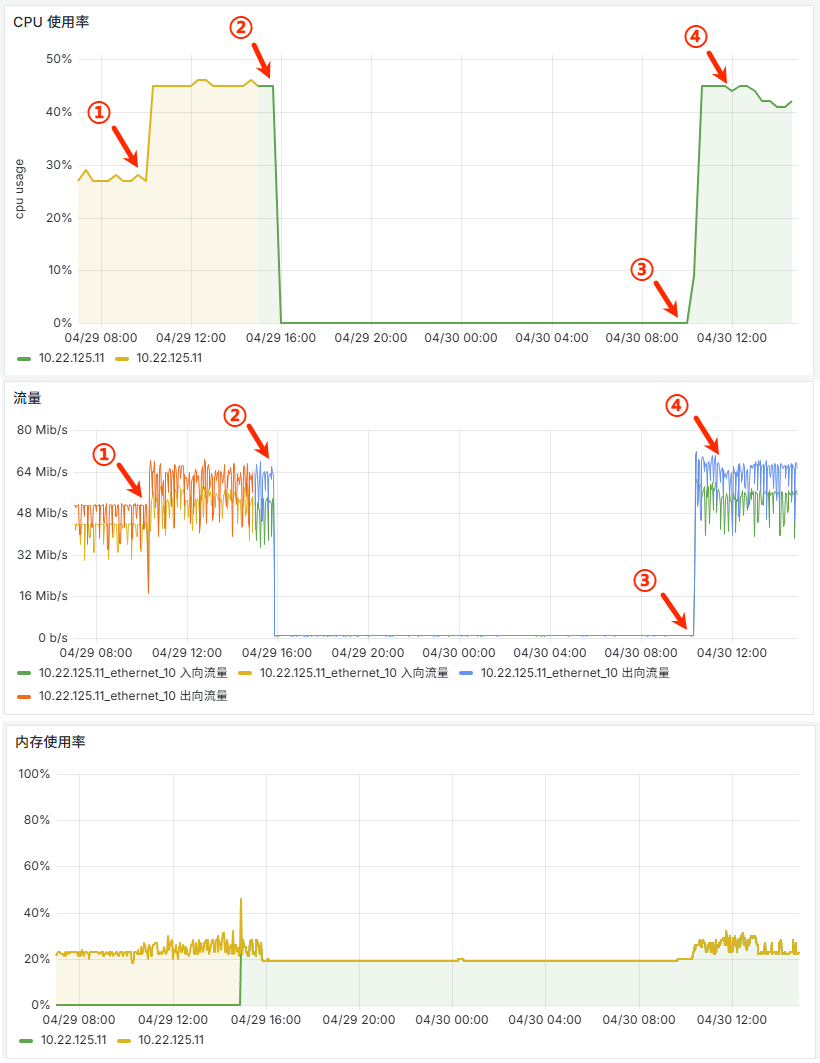
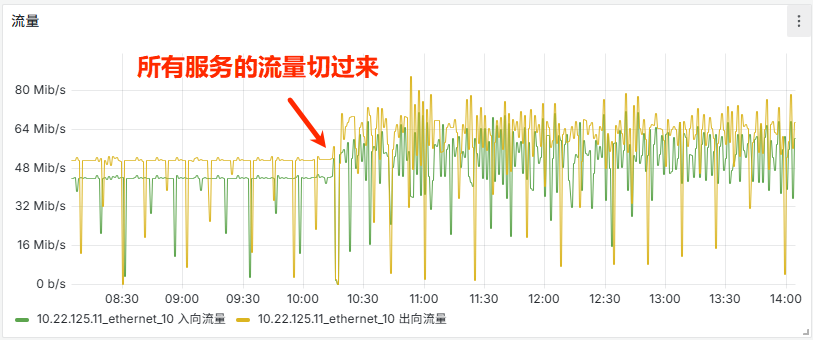
10.22.125.11从 4c4g 调整至 8c8g,为后期增加连接做准备。 - 2026年4月29日10:15 【①】将 HIS、EVT、MRK 所有服务的 CVS 链接,都切换至
10.22.125.11。 - 2026年4月29日10:30 发现异常现象(见下面章节),评估后不影响线上业务,故没有配置回退。
- 2026年4月29日14:26 晓芒申请了新的虚机
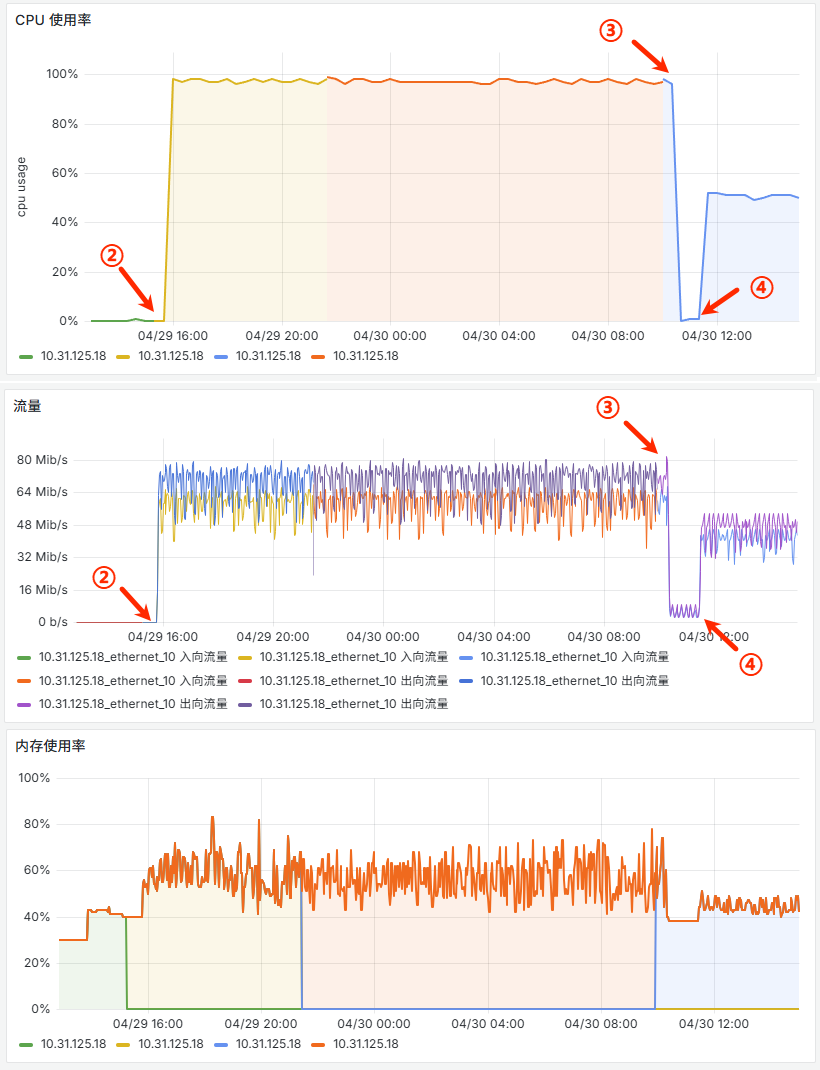
10.31.125.18(2c2g),部署了 CVS,作为后续大数据方向专用的 CVS 机器。 - 2026年4月29日15:47 【②】杨宏修改 DHL 配置时,统一将 CVS 连接改到了
10.31.125.18,但因为 CVS 配置是在 TKService.ini 中的,且 DHL 是与 EVT、HIS、MRK 是混部的,所以此刻 EVT、HIS、MRK 的 CVS 请求也都被切到了新的10.31.125.18上。 - 2026年4月30日10:00 晓芒、杨宏、我拉了个小会,讨论确定了 CVS 后续的操作步骤(如下)。
- 2026年4月30日10:16 【③】杨宏把有 EVT、HIS、MRK 的虚机的 CVS 配置都切回了
10.22.125.11。 - 2026年4月30日11:18 【④】把 EVT 的 “通用集群CMT” 的流量切换到了
10.31.125.18。
两台虚机的监控和节点如下所示:
10.22.125.11
10.31.125.18
三、异常现象与分析
1. CVS 偶尔拉取失败
将 CVT、HIS、MRK 的 CVS 节点都切到 10.22.125.11 上时,会出现如下异常现象:
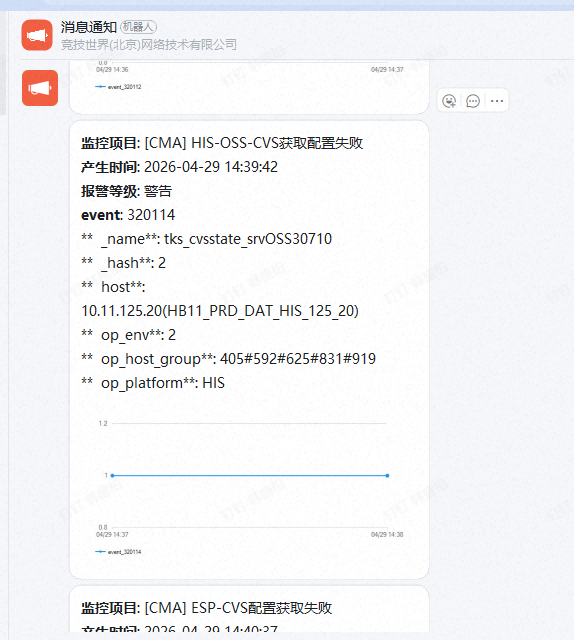
CMA 报警:
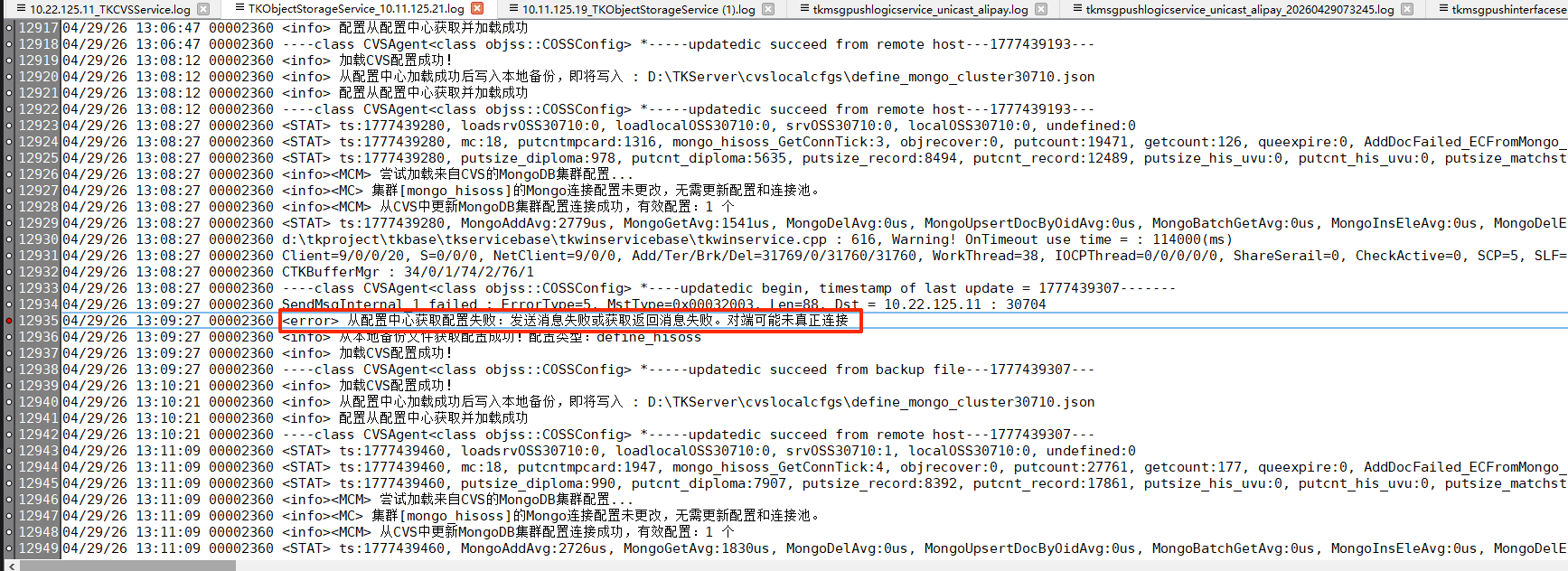
服务获取 CVS 配置失败的日志:
原因分析:
消息发送超过 60s 未得到返回消息,连接中断并触发报警和报错信息。
长时间没有返回消息的原因猜测是目标 CVS 达到性能上限,详见后面分析。
2. CMA 上报数据翻倍
将 CVT、HIS、MRK 的 CVS 节点都切到 10.22.125.11 上时,所有与该服务连接的服务上报的 CMA 指标数据都会翻倍,并且每分钟数据有漏报的情况。
CMA 监控截图:
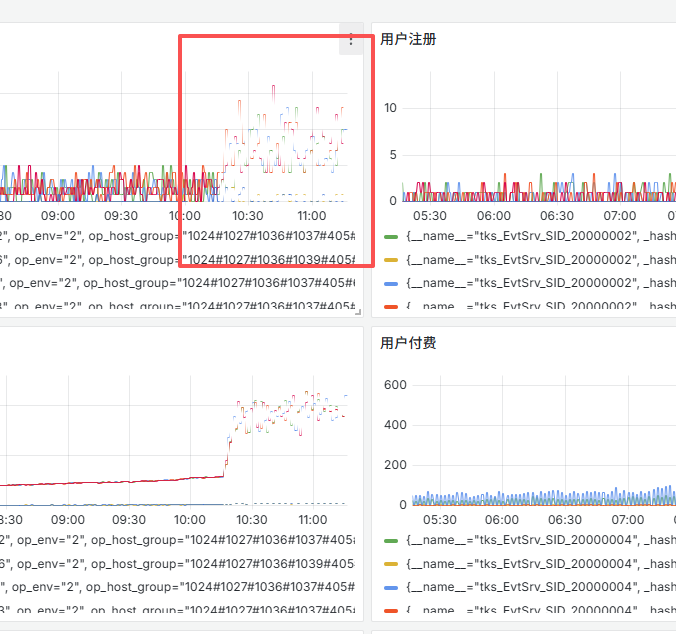
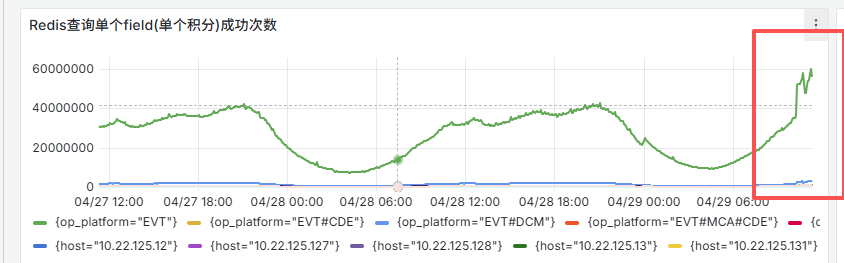
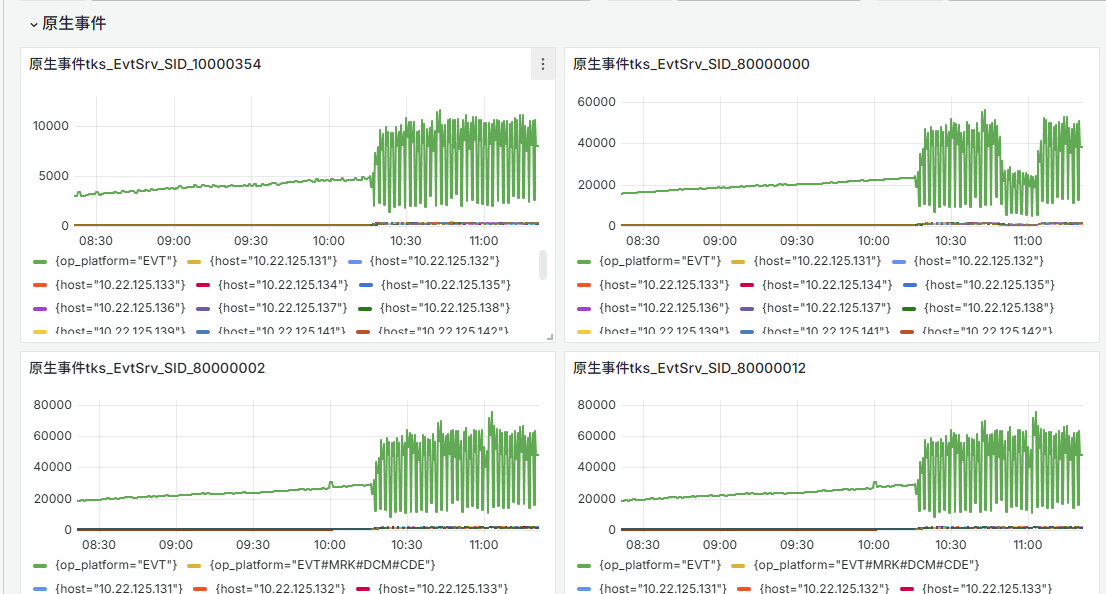
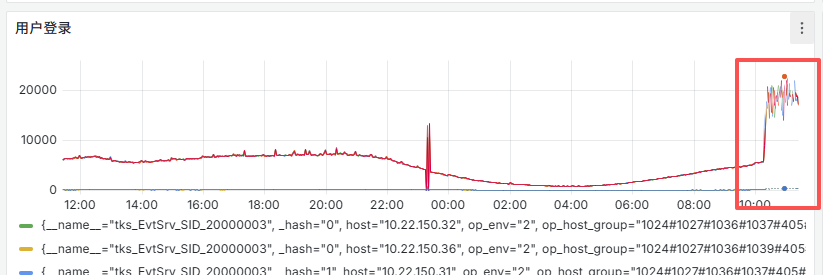
原因分析:
所有流量都切过来时,10.22.125.11 上的 CVS 达到了性能瓶颈,请求返回时长巨增。
拉取 CVS 配置是在 TK 的 OnTimeout() 函数里,因为拉 CVS 配置的响应时间变长了,导致原本应该是一分钟一次的 OnTimeout 变成了 2 分钟,甚至 3 分钟一次。
导致现在上报的指标实际是 2 分钟或者 3 分钟的,所以看起来指标翻倍了,实际上并没有变化。
3. CVS 所在机器流量大
将所有服务的 CVS 节点都切到 10.22.125.11 上后,该虚机的出入流量最高达到了 8MB/s,监控如下:
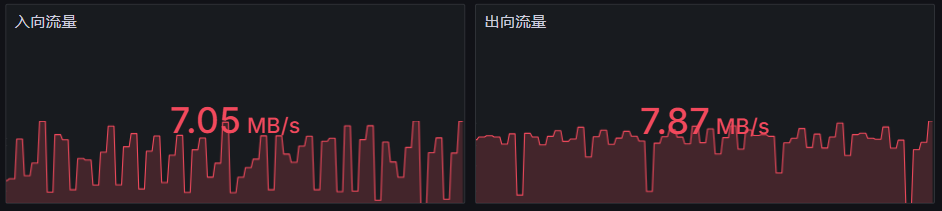
原因分析:
EVT-NOS 的配置太大了,单次请求的 json 配置就达到了 30MB,这些 json 数据都放在 TK 后缀里发送,再加上 EVT 有一百多台机器,每台机器每分钟都会请求一次 CVS,常规情况下,仅 EVT 造成的流量就会达到 50 MB/s,这个流量非常高了,虽然可能不会达到硬件设备的上限(带宽、硬盘),但从系统架构设计的角度出发,这绝对不是合理的存在。
四、根因与改进
1. CVS 性能瓶颈
为什么会出现性能瓶颈:
- 流量与请求量突增:原双节点分担负载,切到单节点后流量瞬间翻倍,CPU、内存、网络收发队列全面承压。
- 单次配置包巨大:单次返回 30MB JSON,CVS 需频繁做内存分配、序列化、拼接、发送,CPU 与内存拷贝开销极高。
- CVS 服务模型限制:CVS 为常规配置服务,未针对 “大报文、高并发、长连接队列” 做优化,请求堆积后处理不过来。
- 同步阻塞模型:CVS 采用同步应答,一个慢请求会阻塞后续请求,形成队头阻塞,时延整体被拉高。
- 虚机资源上限:即便升级到 8c8g,在 “大内存拷贝 + 高频大报文发包” 场景下,依然容易触达单进程瓶颈。
改进方向:
- CVS 服务内增加泳道,高延迟请求(NOS)至少不要堵塞其他服务的请求(HIS、MRK 等)。
- CVS 相关协议启用压缩传输(gzip/deflate),降低报文体积与带宽占用。
- 调整 CVS 的线程池/异步发送逻辑,提升大报文吞吐能力。
- 业务服务(EVT、HIS)增加本地缓存 + 增量拉取,避免全量拉取。
2. JSON 配置后缀过大(详细分析 + 整改思路)
现状问题:
- EVT-NOS 单次配置达到 30MB,全部放在 TK 后缀里随请求返回。
- 上百台机器每分钟拉一次,仅 EVT 就可产生 50MB/s 流量,切到单节点后的实际峰值也有 8MB/s。
- 大报文导致:CVS 处理慢、网络占用高、时延飙升、客户端解析耗时长。
整改思路:
- 配置拆分
- 按模块、按场景、按集群拆分成多个小配置,不一次性全量拉取。
- 客户端按需拉取,不拉无关配置。
- 启用压缩
- 传输层启用 gzip/zstd 压缩,30MB 通常可压到 3–6MB,流量直接降 80%。
- 增量拉取(最关键)
- 配置加版本号/MD5,只拉变更部分,不拉全量。
- 无变更时直接返回 304,大幅降低流量与CPU。
- 本地缓存 + 定时兜底
- 客户端本地缓存配置,CVS 不可用时不阻塞业务。
- 后台异步更新,不影响主线程与定时周期。
- TK 后缀瘦身
- 超大配置不放在 TK 后缀透传,改为独立配置通道。
- 分离静态大配置与高频小配置。
- CVS 服务端分片下发
- 超过阈值自动分片,客户端合并,避免单包过大导致丢包/超时。
3. CMA 监控每分钟上报
问题根源:
- CMA 指标上报依赖 TK 框架的
OnTimeout()定时周期(1 分钟一次)。 - 同步拉取 CVS 配置时,CVS 变慢 →
OnTimeout()被阻塞 → 周期拉长到 2–3 分钟。 - 监控把 2~3 分钟数据合并成 1 分钟显示,造成 “指标翻倍” 假象。
影响:
- 监控失真、误告警、误判业务流量暴涨。
- 无法真实反映业务实时状态。
改进方向:
OnTimeout()中移除高延时操作。可以考虑为 CVS 配置拉取建立单独的定时器,这样还可以手动控制配置拉取的周期。- CMA 服务内应该对指标数据做处理,与上报周期做耦合,给出真实的每分钟数据。
- 增加周期漂移监控,及时发现异常。
4. CVS 同步请求
问题:
- 配置拉取使用 同步阻塞调用,在 TK 框架的
OnTimeout()中串行执行。 - CVS 时延一高,直接拖长整个定时函数执行间隔。
- 无超时保护、无异步、无熔断,一个环节慢全线慢。
风险:
- 配置服务异常 → 定时任务漂移 → 指标异常 → 监控误报。
改进方向:
- 改为 异步拉取,不阻塞定时主线程。
- 我看当前 NOS 中是有异步拉取设计的,但是没有生效,可能是某个前人自己写着玩的。
- 可以考虑用 C++17 中提供的现成的异步框架实现,练练手顺便。